Yiyuan
Wednesday, August 20, 2025 | 2 minutes
高并发IoT平台架构设计:从硬件到应用的完整技术栈解析
高并发IoT平台架构设计:从硬件到应用的完整技术栈解析
在物联网(IoT)快速发展的今天,如何设计一个能够支撑海量设备接入、实时数据处理和高并发访问的平台架构,成为了技术架构师面临的重要挑战。本文将深入解析一个经过实践验证的高并发IoT平台架构,从硬件层到应用层,全面剖析其设计思路和技术选型。
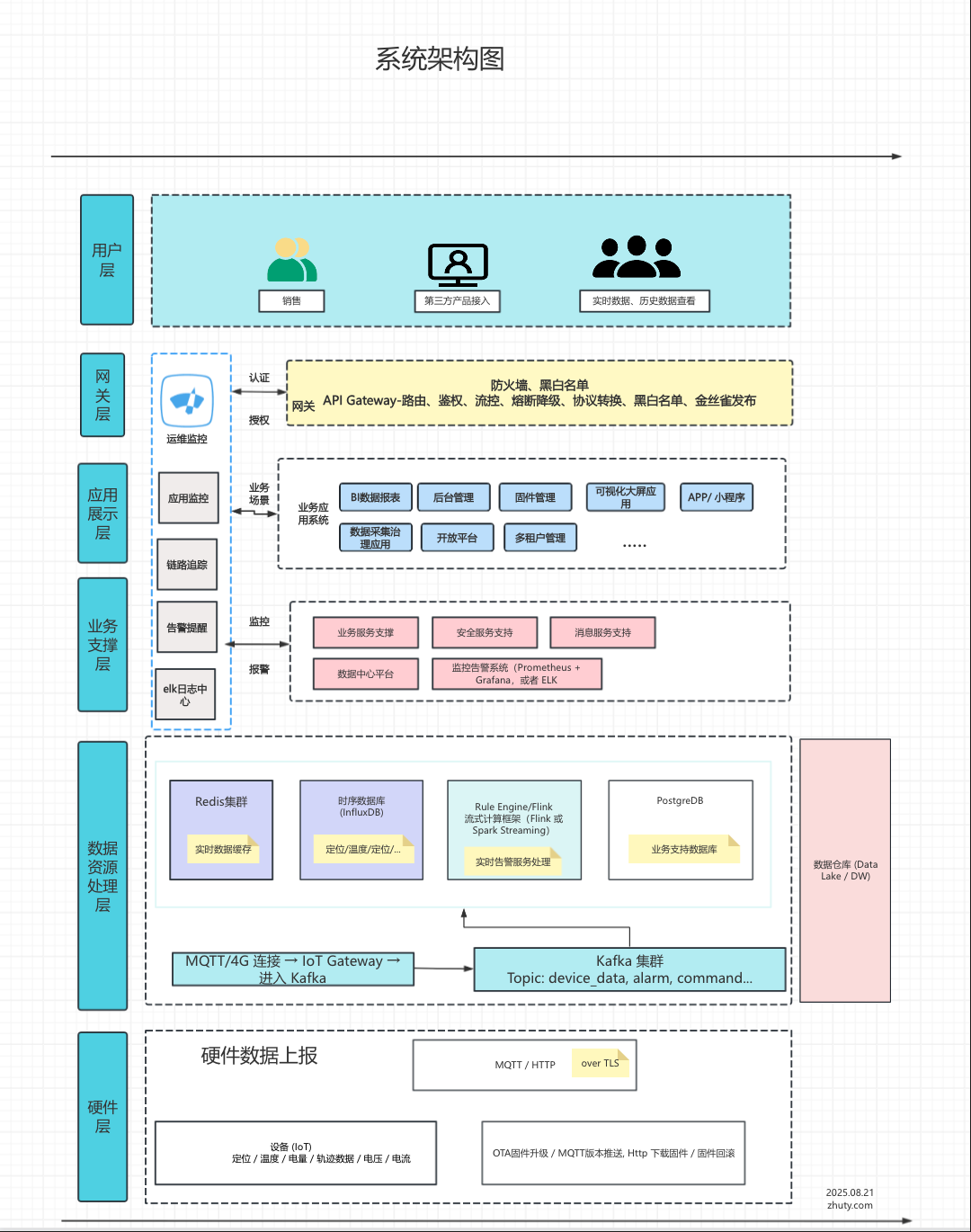
一、架构概览
该IoT平台采用分层架构设计,从上到下分为六个核心层次:
- 用户层 - 提供多样化的用户交互界面
- 网关层 - 统一的API网关和安全控制
- 应用展示层 - 各类业务应用系统
- 业务支撑层 - 核心服务和监控体系
- 数据资源处理层 - 数据存储和实时处理
- 硬件层 - IoT设备和数据采集
二、核心架构层详解
2.1 用户层:多元化接入方式
用户层支持多种接入方式,满足不同场景需求:
- 销售团队:通过专业的管理界面进行设备管理和数据分析
- 第三方产品接入:提供标准化API,支持外部系统集成
- 实时数据查看:支持实时监控和历史数据查询
设计要点:
- 响应式设计,支持多端访问
- 权限分级管理,确保数据安全
- 实时数据推送,提升用户体验
2.2 网关层:统一入口和安全控制
网关层是整个系统的统一入口,承担着重要的安全和流量控制职责:
核心功能模块:
安全控制
- 认证(Authentication):验证用户身份
- 授权(Authorization):控制访问权限
- 黑白名单:基于IP和用户的行为控制
流量管理
- 流控(Flow Control):防止系统过载
- 熔断降级(Circuit Breaking):保护下游服务
- 金丝雀发布:灰度发布新功能
协议适配
- 协议转换:支持多种通信协议
- 路由转发:智能路由到后端服务
技术选型建议:
# 推荐技术栈
API Gateway: Kong / Zuul / Spring Cloud Gateway
认证授权: OAuth2.0 + JWT
限流熔断: Sentinel / Hystrix
监控: Prometheus + Grafana
2.3 应用展示层:业务应用矩阵
应用展示层包含多个业务系统,每个系统都有其特定的职责:
核心应用系统:
数据可视化
- BI数据报表:商业智能分析
- 可视化大屏:实时监控大屏
- APP/小程序:移动端应用
设备管理
- 固件管理:OTA升级和版本控制
- 后台管理:设备配置和用户管理
开放能力
- 开放平台:第三方开发者接入
- 多租户管理:SaaS化支持
技术特点:
- 微服务架构,服务独立部署
- 容器化部署,支持弹性伸缩
- 链路追踪,便于问题定位
2.4 业务支撑层:服务治理和监控
业务支撑层提供核心的基础服务能力:
监控告警体系:
监控系统
- Prometheus + Grafana:指标监控和可视化
- ELK Stack:日志收集和分析
- 链路追踪:分布式调用链监控
告警机制
- 多级告警策略
- 多渠道通知(邮件、短信、钉钉等)
- 告警抑制和聚合
核心服务支撑:
消息服务:基于Kafka的消息队列 安全服务:统一的身份认证和权限管理 业务服务:核心业务逻辑处理
2.5 数据资源处理层:数据流转核心
这是整个架构的核心层,负责数据的接收、存储和处理:
数据接入流程:
IoT设备 → MQTT/4G → IoT Gateway → Kafka集群
数据流转特点:
- 高吞吐:Kafka集群支持百万级TPS
- 低延迟:端到端延迟控制在毫秒级
- 高可靠:多副本机制保证数据不丢失
存储架构设计:
实时数据缓存
- Redis集群:热点数据缓存
- InfluxDB:时序数据存储(温度、位置、电量等)
业务数据存储
- PostgreSQL:结构化业务数据
- 数据仓库:历史数据分析和报表
技术选型理由:
Redis: 内存数据库,毫秒级响应
InfluxDB: 专为时序数据优化
PostgreSQL: 强一致性,支持复杂查询
数据仓库: 支持大规模数据分析
实时处理引擎:
Flink流式计算
- 实时告警处理
- 数据清洗和转换
- 复杂事件处理(CEP)
规则引擎
- 动态规则配置
- 实时规则匹配
- 告警触发机制
2.6 硬件层:设备接入和管理
硬件层负责IoT设备的接入和固件管理:
设备接入协议:
通信协议
- MQTT over TLS:轻量级消息传输
- HTTP over TLS:RESTful API调用
- 4G/5G:蜂窝网络接入
数据采集类型:
- 位置信息(GPS坐标)
- 环境数据(温度、湿度)
- 设备状态(电量、电压、电流)
- 轨迹数据(移动路径)
设备管理能力:
OTA固件升级
- 增量升级,节省流量
- 版本回滚,保证稳定性
- 升级进度监控
设备监控
- 在线状态监控
- 数据上报频率控制
- 异常设备识别
三、高并发设计要点
3.1 水平扩展策略
网关层扩展
- 无状态设计,支持多实例部署
- 负载均衡,分散请求压力
- 自动扩缩容,根据流量调整
数据处理层扩展
- Kafka分区机制,支持并行处理
- Flink集群,支持任务并行
- 数据库读写分离,提升查询性能
3.2 缓存策略
多级缓存
- L1缓存:应用本地缓存
- L2缓存:Redis集群缓存
- L3缓存:CDN边缘缓存
缓存更新策略
- 写穿策略:保证数据一致性
- 缓存预热:系统启动时预加载
- 缓存穿透防护:布隆过滤器
3.3 异步处理
消息队列解耦
- 生产者和消费者解耦
- 削峰填谷,平滑流量波动
- 失败重试,提高系统可靠性
异步任务处理
- 耗时操作异步化
- 批量处理,提升效率
- 任务优先级管理
四、性能优化策略
4.1 数据库优化
索引优化
- 复合索引设计
- 分区表策略
- 查询语句优化
连接池管理
- 连接池大小调优
- 连接复用机制
- 慢查询监控
4.2 网络优化
CDN加速
- 静态资源CDN分发
- 就近访问,减少延迟
- 带宽成本优化
协议优化
- HTTP/2多路复用
- 数据压缩传输
- 连接复用
4.3 监控和调优
性能监控
- 关键指标监控(QPS、响应时间、错误率)
- 资源使用监控(CPU、内存、磁盘、网络)
- 业务指标监控(设备在线率、数据处理量)
容量规划
- 基于历史数据预测
- 弹性扩容预案
- 成本效益分析
五、技术选型总结
5.1 核心技术栈
| 层级 | 技术选型 | 选择理由 |
|---|---|---|
| 网关层 | Kong/Spring Cloud Gateway | 高性能、功能丰富 |
| 消息队列 | Kafka | 高吞吐、持久化 |
| 缓存 | Redis | 高性能、数据结构丰富 |
| 时序数据库 | InfluxDB | 专为时序数据优化 |
| 流处理 | Flink | 低延迟、高吞吐 |
| 监控 | Prometheus + Grafana | 生态完善、可视化强 |
5.2 部署架构
容器化部署
- Docker容器化应用
- Kubernetes编排管理
- 服务网格(Istio)治理
微服务架构
- 服务拆分原则
- 服务间通信机制
- 服务发现和注册
六、最佳实践建议
6.1 架构设计原则
- 分层解耦:各层职责清晰,降低耦合度
- 水平扩展:支持无状态扩展,提升系统容量
- 容错设计:多级容错机制,保证系统可用性
- 监控先行:完善的监控体系,快速定位问题
6.2 开发规范
- API设计规范:RESTful API设计,版本管理
- 数据格式标准:统一的数据格式和编码规范
- 错误处理机制:统一的错误码和异常处理
- 日志规范:结构化日志,便于问题排查
6.3 运维保障
- 自动化部署:CI/CD流水线,快速发布
- 灰度发布:金丝雀发布,降低发布风险
- 灾备方案:多机房部署,数据备份策略
- 安全防护:网络安全、数据安全、应用安全
在实际实施过程中,需要根据具体的业务场景和技术团队能力,对架构进行适当调整和优化。同时,持续的技术演进和性能优化也是保证系统长期稳定运行的重要保障。
本文基于实际项目经验总结,如有疑问或建议,欢迎交流讨论。